CPU実験が終わったので、作ったものの紹介と、やってよかったこと、CPU実験全体としての感想を書いていく。
作ったもの 見出しへのリンク
RISC-VベースのISA RINANA、コンパイラ mincc、余興としてコアの上で動くシミュレーター rinacoreを作った。
1. RISC-VベースのISA: RINANA 見出しへのリンク
CPU実験の第1週の初仕事として、RINANAというISAをRISC-Vを参考にして作った。1
一旦RISC-Vで実装し始めて、コアが完動してから2nd ISA、3rd ISAと移行していく班が多かったが、我々の班は最初からRINANAで作ることにした。これにより仕様の違いによる混乱を避け、バージョン改訂によるコアの作り直しやシミュレーターの移行コストを最小限にすることを狙った。
ISAの定義や認識が複数人で割れてしまったり複数バージョンが同時に存在したりすることを避けるために、オペコードの割り振りや新命令の追加などのISAに関係する仕様の策定の最終決定権とバージョン管理の責任を、班員の同意を取った上で全て自分に集約させた。
最初の段階では、RISC-Vからfence.i等の明らかに余興でも使わない命令を除いてオペコードを振り直し、B-typeやJ-typeの11bit目のような飛んでいるbitをわかりやすいように並べ替えただけのものであった。その後、コンパイラで必要になった命令の追加やコア係からの要望であるfloat命令かどうかを見分けられるbitの追加などを行い実に13回のアップデートを経て、最終的なRINANA v1.1.0が完成した。
RINANAを真面目にversioningしたことと、バージョンが上がるたびに最優先事項として班のアセンブラr72bとシミュレーターを更新してもらったことで、参照するRINANAのバージョン違いによる混乱は最小限に抑えられたと考えている。また、ISAを管理する仕事をコンパイラ係が行うことで、コア係が求める仕様やコンパイラ係が必要としている機能を相互に理解することができ、コミュニケーションが取りやすくなるという副次的な効果もあった。多分コア係がISAを定義しても同等の効果が得られると思う。
2. コンパイラ: mincc 見出しへのリンク
せっかくのCPU実験ということでmincamlやmincaml-rsなどの出来合いのコンパイラに頼らずに書きたいという想いが強く、Haskellを使ってフルスクラッチで作成した。Haskellを選択したのは、個人的に経験が浅いあるいは全くないかつ面白そうな言語を使いたかったからで、該当するJulia, Nim, Gleam, F#の中から選んだ。結果的にHaskellで頻出の諸概念とお友達になれたのでかなり良い選択だったと思う。シミュ完動したのは12/19 0:59だった。
コンパイラを実装する上で2つのルールを自分に課した。mincamlやmincaml-rsのソースコードをそのまま移植しないことと、過去のコンパイラ係が残したブログや最適化に関する本を一切参考にしないことである。3前者は、元からあるコンパイラをただ別言語に移植しただけでは「フルスクラッチ」ということはできないという信念からである。後者は、過去のコンパイラ係のブログを読むと、その人が思う最適解を知ってしまうので、試行錯誤の余地が削られてしまうのではないか、と考えたからである。後者については後ほど改めて言及する。
フルスクラッチする上で障害となったのは、mincamlの構文が「仕様 = 実装」となっているところである。一応資料はあるものの優先順位や具体的な構文に曖昧な部分が多く、パーサーを書くためにmincamlの実装を腰を据えて読み解く必要があった。それ以外は、時間こそかかるもののしがらみもないので伸び伸びと実装を行うことができた。
コンパイラ係でこの記事を見ている人が一番気になるのは最適化であろう。残念なことにminccには「新規性のある」最適化は多分積まれていないと思う。ここで「思う」と言ったのは、過去のコンパイラ係のブログを読んでいないので、どれが「新規性のある」ものかどうかわからないからである。少なくとも、2ヶ月間で編み出したものが既出でないとは到底思えないのでこのような書き方をした。
さて、minccでは最適化はmiddle-endとback-endでそれぞれ独立して行われる。まず、Middle-endで行われる最適化を列挙しよう。名前はその最適化が実装されているモジュール名をそのまま利用している。
| 最適化 | 説明 |
|---|---|
| BoolOperations | if文のうち、bool演算を使って書けるものを展開する。例えば、if a then not b else bをxor a bに変換する。 |
| CompMerging | if文のうち、let a = b < c in .... in if a then d else eのようなものをif b < c then d else eに変換する。 |
| ConstFold | 定数畳み込み。 |
| CSE | 共通部分式削除をする。式がpureかどうかの判定はかなり甘い。 |
| IfMerging | if c then let a1 = b in ... else let a2 = b in ...をlet a = b in if c then ... else ...に変換する。最適化というよりはコードサイズ削減のために入れている。 |
| Inlining | 関数のインライン化をする。 |
| LoopArgsElim | loop a := b eのうち、aがeで変更されない場合、aを削除する。 |
| LoopDetection | 再帰関数からループを検出し、loop文に変換する。 |
| ReadOnly | 1度しか書き込みが起こらない配列を検知し、変数に分解する。 |
| StripCondition | if c then let ... in 1 else let ... in 0をlet () = if c then let ... in () else let ... in () in cにする。if文の結果により次のif文の分岐が決まるパターンに利く。 |
| SwapIf | if c then ... else ()をif c then () else ...にする。 |
| UnusedElim | 不要定義削除。 |
| VarMerging | let a = b in eを[b/a]eにする。 |
Back-endではLLVMのBasicBlockのような形式でコードを保持している。Back-endでの最適化は、以下の通りである。
| 最適化 | 説明 |
|---|---|
| ArgsReg | callやblockの終端、再代入を跨がない範囲で、mov rd, anの後のrdの出現をanで置き換える。 |
| ArgsRegRev | callやblockの終端、再代入を跨がない範囲で、mov an, rdの前のrdの出現をanで置き換える。 |
| CloneRet | retで終わるblockに合流している場合、blockを複製する。 |
| EmptyBlockMerging | Phiノードしかないjmpが終端のblockを次のblockと合体させる。 |
| Fusion | 命令を融合する。RINANAにはfmaddが定義されているので、faddとfmulを合体させる。 |
| Merging | jmpが終端のblockとその次にある合流のないblockを合体させる。 |
| MulElim | 2の冪乗の掛け算をシフト命令で置き換える。 |
| RegMerging | mov rd, rsとなっている時、phiノードの整合性が取れるならrdをrsで置き換える。 |
| Unreachable | 到達不可能なblockを削除する。 |
| UnusedReg | 使われていないレジスタを削除する。レジスタ割り当てとspillingに使っている生存区間解析のコードを流用しているため、blockを超えて判定され、精度は良い。 |
| UseZeroReg | mov rd, zeroとなっている時、phiノードの整合性が取れるならrdをzeroで置き換える。 |
この中で説明が必要なのはEmptyBlockMergingだろう。minccにおいてEmptyBlockMergingはphiノードのみから構成されているブロックと次のブロックを下図のように合成する。
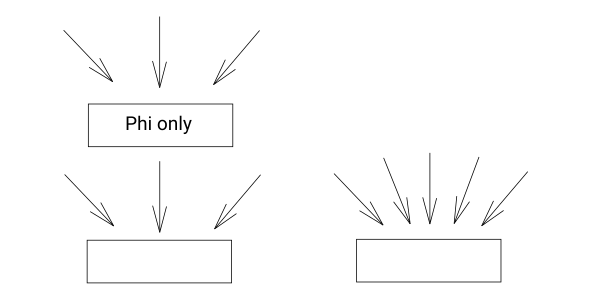
EmptyBlockMergingのイメージ (左: 最適化前, 右: 最適化後)
ただ、この最適化には「落とし穴」がある。この方法を愚直にやってしまうと、以下のようにphiノードのみからなるブロックとその次のブロックが共通のブロックからの直接のパスを持つ場合にphiノードの整合性が取れなくなる。整合性が取れなくなるというのは、同じブロックに合成されてしまった時に、同じブロックからくる別のレジスタを指定するphiノードが生成されることを指す。このような場合に注意すればEmptyBlockMergingは安全に適用可能である。
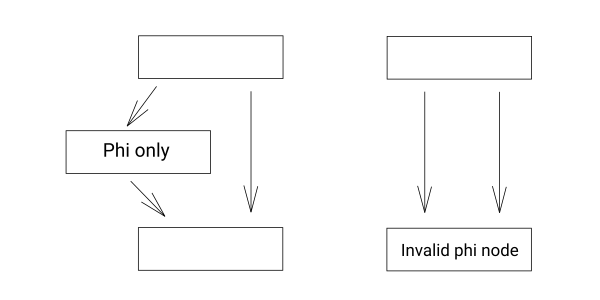
EmptyBlockMergingをしてはいけない例 (左: 最適化前, 右: 最適化をしてしまった場合)
以上の最適化を実装して128x128のminrtは1,602,464,283命令で実行できる。IS24erの他の班を見ている限り、これくらいやれば13,14億くらいはいけると思ったのだが、16億止まりだった。心当たりがあるとすれば、コードサイズを小さくするためにループアンローリングを一切していないことくらいだろうか。一応、デフォルトで無効化されているFusionを有効化すると、1,581,147,817命令まで縮むが大した差ではない。
2.1 minccの実装のこだわりポイント 見出しへのリンク
mincamlやmincaml-rsのソースコードに目を向けると、型なしの式、型付きの式、K正規形、クロージャー変換後の式など各レイヤーごとに式が別々に定義されている。そして、式が同じように定義されるたびに、似たようなユーティリティ関数が実装されている。これは大変冗長で非効率であると感じたので、minccではGADTsを用いて式を1つの型コンストラクタExprで定義し、その型コンストラクタの引数の型で式の種類を表現することで定義を一元化した。より具体的には、以下のような定義を行なっている。
まず、式の種類を表現する型クラスExprKindを定義した。AllowLoopのように式の性質がBool値で表せるようなものに関してはDataKinds拡張を用いて表現を行なっている。またTypeFamilies拡張も必要であることに注意されたい。
class ExprKind ty where
type StateTy ty :: Type
type IdentTy ty :: Type
type OperandTy ty :: Type
type AllowBool ty :: Bool
type AllowBranch ty :: Bool
type AllowLoop ty :: Bool
type AllowClosure ty :: Bool
これを用いて、例えば、「型付きでK正規系であり、bool値をint値として扱い、クロージャーを許す式」の種類を表現する型ClosureExprKindは以下のように定義できる。
data ClosureExprKind
instance ExprKind ClosureExprKind where
type StateTy ClosureExprKind = PTypedState
type IdentTy ClosureExprKind = Ident
type OperandTy ClosureExprKind = Ident
type AllowBool ClosureExprKind = False
type AllowBranch ClosureExprKind = True
type AllowLoop ClosureExprKind = True
type AllowClosure ClosureExprKind = True
今、定義したExprKindを用いて、Expr型を以下のように記述したとしよう。定義にはGADTs拡張やTypeOperators拡張が必要である。
data Expr kind where
Const ::
StateTy kind ->
Literal (AllowBool kind) ->
Expr kind
Unary ::
StateTy kind ->
UnaryOp ->
OperandTy kind ->
Expr kind
Binary ::
StateTy kind ->
BinaryOp ->
OperandTy kind ->
OperandTy kind ->
Expr kind
...
App ::
(AllowClosure kind ~ False) =>
StateTy kind ->
OperandTy kind ->
[OperandTy kind] ->
Expr kind
...
Continue ::
(AllowLoop kind ~ True) =>
StateTy kind ->
[IdentTy kind] ->
Expr kind
MakeClosure ::
(AllowClosure kind ~ True) =>
StateTy kind ->
IdentTy kind ->
[OperandTy kind] ->
Expr kind
ClosureApp ::
(AllowClosure kind ~ True) =>
StateTy kind ->
IdentTy kind ->
[OperandTy kind] ->
Expr kind
...
この時、GADTsの恩恵により、型に応じて使われるコンストラクタ、使われないコンストラクタを静的に決定でき、書くべき条件分岐が減る。例えば、Expr ClosureExprKind型の場合、上記の定義からAppコンストラクタは来ないということがわかるので、case式でAppとマッチする場合を記述しなくて良い。同様に、ループがないことが型レベルで保証されている場合、ループの場合の処理を記述しなくて良い。これにより、コードの冗長性が減り、可読性が向上した他、認知コストも減少した。しかも、一般のExpr kindに対してユーティリティ関数を実装することで、全ての式に対して共通の処理を行うことが容易になった。
このようなTypeFamiliesとGADTsの合わせ技は式だけでなく、back-endの中間表現でも用いられており、phiノードが存在するかどうかや、レジスタの生存区間の情報を保持しているかどうかが型によって表現されている。これにより、back-endにおいても同様の恩恵を受けることができた。
同様に、レジスタを表す型にもintかfloatかの情報を付与した。これにより、intとfloatのレジスタがどのようなパターンで来るかを型レベルで保証することができるようになった。例えば、比較命令のコンストラクタは以下のように定義した。
ICompOp ::
InstStateTy ty ->
RelationBinOp ->
Register Int ->
Register a ->
RegOrImm a ->
Inst ty
このような定義をすることで、比較する対象のレジスタの型が一致していることや、戻り値が格納されるレジスタがintであることが型レベルで保証できた。
ところで、intレジスタとfloatレジスタを分けると、それぞれのレジスタに対して情報を持ちたい場面が発生する。例えば、レジスタの使用数のカウンタを定義したければ、データ型を定義して、intの場合とfloatの場合それぞれ持っておく必要がある。つまり、
data RegCounter = RegCounter
{ counter :: Int
}
として、(RegCounter, RegCounter)を持っておきたくなる。他にも、intレジスタとfloatレジスタの生存しているレジスタの集合を持ちたい場面もある。この時は、型コンストラクタにしてしまって、
data RegLiveness a = RegLiveness
{ liveness :: Set (Register a)
}
として、(RegLiveness Int, RegLiveness Float)と持っておけば良いだろう。さて、このようなintレジスタとfloatレジスタで別々の情報を持っておく機能を一般化したい。この時、一番最初に思いついたデータの持ち方は以下のようなものだった。
-- | 前者の場合
data RegMultiple a
= RegMultiple
{ iTuple :: a
, fTuple :: a
}
-- | 後者の場合
data RegVariant f
= RegVariant
{ iVariant :: f Int
, fVariant :: f Float
}
これならば、先ほどの例を用いて言えばRegMultiple RegCounterやRegVariant RegLivenessとして、intレジスタとfloatレジスタで別々の情報を持つことができる。実際、これで実用上の問題はなかった。
ただ、やはりこの2つの型を別々に定義するのは冗長ではないかと思えてくる。なぜなら、量化を除けば、この2つは非常に似た構造を持つように思えるからだ。例えば、指定した型の方の値を取り出す関数や、intの場合とfloatの場合のいずれもを射影する関数、intの場合とfloatの場合のいずれかを射影する関数は似通っている。
-- | 指定した型の方の値を取り出す関数
rget :: RegType t -> RegMultiple a -> a
rget :: RegType t -> RegVariant f -> f t
-- | intの場合とfloatの場合のいずれもを射影する関数
rmap :: (a -> b) -> RegMultiple a -> RegMultiple b
rmap :: (forall a. f a -> g a) -> RegVariant f -> RegVariant g
-- | intの場合とfloatの場合のいずれかを射影する関数
rmap :: RegType t -> (a -> a) -> RegMultiple a -> RegMultiple a
rmap :: RegType t -> (f t -> f t) -> RegVariant f -> RegVariant f
この2つを統合するのは実はそこまで容易くない。それはRegMultiple aのaとRegVariant fのfのkindの違いに由来する。RegMultiple aのaはTypeであるが、RegVariant fのfはType -> Typeである。それゆえ、kindの違いからコンパイラの型チェックを通すことが困難になる。
妥協するならば、この問題はダミーの型変数を導入することでRegMultipleを廃止しすべての場合をRegVariantで記述することで解決する。つまり、先ほどの例で言えば、
data RegCounter dummy = RegCounter
{ counter :: Int
}
としてしまうということである。これならばkindをType -> Typeに統一することでkindの違いによる型エラーを防ぐことができる。しかし、全く使っていない型変数を用意するのは心情的には抵抗があった。
1ヶ月ほどの格闘の末、最終的に以下のような型族を用いた型クラスを定義することで問題は解決した。
-- | Holds two objects - one is for integer registers and the other is for float registers.
class RegTuple f where
type RegTupleMap f rTy
infixl 9 #!!
(#!!) :: f -> RegType rTy -> RegTupleMap f rTy
createRT :: RegTupleMap f Int -> RegTupleMap f Float -> f
このように定義すると、RegMultipleとRegVariantはそれぞれ以下のように定義・実装できる。
-- | Intとfloatで同じ型を持つ場合
data RegMultiple a
= RegMultiple a a
instance (RegTuple (RegMultiple a)) where
type RegTupleMap (RegMultiple a) rTy = a
RegMultiple i _ #!! RInt = i
RegMultiple _ f #!! RFloat = f
createRT = RegMultiple
-- | Intとfloatで同じ型コンストラクタで異なる引数を持つ場合
data RegVariant f
= RegVariant (f Int) (f Float)
instance RegTuple (RegVariant f) where
type RegTupleMap (RegVariant f) rTy = f rTy
RegVariant i _ #!! RInt = i
RegVariant _ f #!! RFloat = f
createRT = RegVariant
また、定義から以下のようにRegMultipleとRegVariantの両方に使えるユーティリティ関数を定義できる。これにより、この2つを共通化して扱うことができるようになり、可読性が向上し、冗長性も減った。
buildRT :: (RegTuple f) => (forall rTy. RegType rTy -> RegTupleMap f rTy) -> f
buildRT f = createRT (f RInt) (f RFloat)
updateRT :: (RegTuple f) => RegType rTy -> (RegTupleMap f rTy -> RegTupleMap f rTy) -> f -> f
updateRT RInt func rt = createRT (func $ rt #!! RInt) (rt #!! RFloat)
updateRT RFloat func rt = createRT (rt #!! RInt) (func $ rt #!! RFloat)
infixl 4 #$
(#$) :: (RegTuple f, RegTuple g) => (forall rTy. RegType rTy -> RegTupleMap f rTy -> RegTupleMap g rTy) -> f -> g
f #$ rt = buildRT $ \regTy -> f regTy $ rt #!! regTy
infixl 6 #<>
(#<>) :: (RegTuple f, Semigroup (RegTupleMap f Int), Semigroup (RegTupleMap f Float)) => f -> f -> f
a #<> b = createRT (a #!! RInt <> b #!! RInt) (a #!! RFloat <> b #!! RFloat)
型クラスの実装に必要な関数も必要最小限まで絞ってあるので、自然な実装が定まり簡単に実装できた。
では話を戻そう。
2.2 minccのバグ 見出しへのリンク
余談ではあるが、minccはシミュ完動するまでたくさんのバグを含んでいた。その中で致命的だったのがif文をback-endの形式に落とすときにelse節からthen節にfall throughするというものである。その結果、minrtが以下のようになってしまった。

バグったminrt
以下がシミュで生成した正常なminrtの結果である。心の目で見比べると「確かに違うけどなんとなく言いたいことはわかる」と思える。多分同じバグを踏む人はこれ以降いないとは思うが、もし上のような結果が出たら 正しいminrtif文の変換を疑うと良いだろう。
ちなみにIS24erの内輪では、我が班で起こったバグとして誤ったマンデルブロー集合、通称「嘘デルブロー集合」が有名4である。よくこれがminccによるものだと誤解されるが、実際はシミュレーターで使われているfloat命令のテーブルが間違っていたことに由来する。禍々しいマンデルブロー集合が出てきた時はfloat演算を疑おう。

通称: 嘘デルブロー集合

正しいマンデルブロー集合
3. コアの上で動くシミュレーター: rinacore 見出しへのリンク
RINANAでRINANAを動かしたいという思いから、RINANAで書かれたRINANAシミュレーター rinacoreを作成した。Rinacoreは入力としてプログラムとプログラムの入力を受け取り、プログラムの出力を返すまさにコアで動くシミュレーターとなっている。
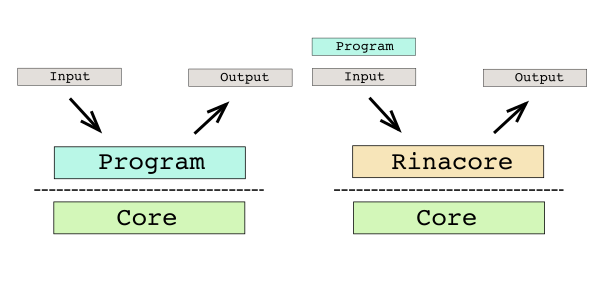
Rinacoreの概要 (左: 通常の実行, 右: Rinacoreを介した実行)
より具体的にはmincamlで命令レベルシミュレーターを実装し、それをminccでコンパイルすることで作った。仕組みはかなり単純で、mincamlの組み込み関数read_intを使って命令列を入力から読み取り、入力列を受け取り切ったら命令をデコードして実行するものになっている。シミュ係が作るcycle-accurateなシミュレーターではなく、コアの仕様を再現することなく1命令ずつ前から順に計算するものとなっている。
一見すぐ作れそうなものであるが、実際にやってみるとmincamlの言語仕様が貧弱なために回りくどいことや少々面倒なことをする必要がある。前提として、mincamlにはbool, int, float, a array, a * bしか型がない。Tupleがあるので気合いでデータ構造を持つことはできるが、簡潔にそれを記述する方法がないので開発する上で混乱を招くこととなる。また、refがないために参照を使うことができない。他にも文字列リテラルや2進数, 16進数表記などに対応していないため、即値の扱いには苦戦することとなる。
もちろん、mincamlの構文を拡張しコンパイラでそれを実装すれば問題は解決しはするが、他の班のコンパイラでも容易に動かせるものを作りたかったので構文や仕様には手を加えないこととした。「7台のコアで動くRINANA」を目指すプロジェクトでもあるからである。
さて、mincamlの仕様上の問題への対処法を紹介する。まず、refについてであるが、少し冗長だが簡単に同等のことができる。実際に長さ1の配列を作成することで以下のように再現可能である。
let x = Array.create 1 314 in (* let x = ref 314 *)
let _ = x.(0) in (* !x *)
let _ = x.(0) <- 42 in (* x := 42 *)
これを使えば、例えばメモリやレジスタなどの関数を超えて扱いたい情報を、関数の引数を使って毎回渡すことなく扱うことができる。5
次に命令デコードなどでbit maskをするときに役に立つ2進数, 16進数リテラルであるが、これの解決策は残念ながらないのでbit maskに用いる数をマジックナンバーとして埋め込んでいる。例えばS-typeの命令の即値を取り出す関数は以下のような実装になっている。
(* get imm when S-type *)
let rec extract_imm_Stype instr =
let lower = p_and 1984 instr in
let upper = p_and (-33554432) instr in
let lower_shifted = p_srl lower 6 in
let upper_shifted = p_sra upper 20 in
p_or lower_shifted upper_shifted
in
1984は0x000007c0に、-33554432は0xfe000000に相当する。暗黙的に負数に補数表現を使っていることを仮定しているが、厳密にはmincamlで負数の扱いの仕様が定められている部分が見当たらないので未定義かもしれない。また、マジックナンバーが大量に出現するので視認性はかなり悪い。
最後に文字列リテラルである。シミュレーターである以上、レジスタやPCを綺麗に表示させる機能をつけたい。そのためには文字列リテラルが欲しいが、string型もchar型もない。そこで、int arrayを文字列と見ることにした。そうすると例えば"rinacore"は以下のように表現できる。
(* "rinacore" *)
let rinacore_str = Array.make 9 0 in
let rec init_rinacore_str dummy =
rinacore_str.(0) <- 114;
rinacore_str.(1) <- 105;
rinacore_str.(2) <- 110;
rinacore_str.(3) <- 97;
rinacore_str.(4) <- 99;
rinacore_str.(5) <- 111;
rinacore_str.(6) <- 114;
rinacore_str.(7) <- 101;
()
in
この調子でシミュレーターで使う文字列を全て定義する必要があるのだが、流石に面倒なので、文字列リテラルを定義するSONファイルからmincamlのソースコードを生成するPythonスクリプトを書いてmakeされたときに自動生成されるようにした。例えば、以下のようなJSONファイルが来たら
[
{
"name": "null_str",
"text": ""
},
{
"name": "rinacore_str",
"text": "rinacore"
},
{
"name": "load_error_str",
"text": "[ERROR] The instruction memory is exhausted."
},
...
]
以下のようなmincamlファイルを生成するようにした。null文字が来るまでprint_charする関数print_strも合わせて定義すると、文字列を気兼ねなく使えるようになり、出力結果の見やすさが向上するほか、シミュレーター自体をprintデバッグすることも容易になった。
(* Generated by str_gen.py *)
(* "" *)
let null_str = Array.make 1 0 in
let rec init_null_str dummy =
()
in
(* "rinacore" *)
let rinacore_str = Array.make 9 0 in
let rec init_rinacore_str dummy =
rinacore_str.(0) <- 114;
rinacore_str.(1) <- 105;
rinacore_str.(2) <- 110;
rinacore_str.(3) <- 97;
rinacore_str.(4) <- 99;
rinacore_str.(5) <- 111;
rinacore_str.(6) <- 114;
rinacore_str.(7) <- 101;
()
in
(* "[ERROR] The instruction memory is exhausted." *)
let load_error_str = Array.make 45 0 in
let rec init_load_error_str dummy =
load_error_str.(0) <- 91;
load_error_str.(1) <- 69;
load_error_str.(2) <- 82;
load_error_str.(3) <- 82;
load_error_str.(4) <- 79;
load_error_str.(5) <- 82;
load_error_str.(6) <- 93;
...
この文字列の実装のおかげで、例えば実行終了時には以下のような出力が"コアから"送られてくる。シミュレーター然とした見た目になっていると自負している。
...
...
PC: 54 RET_ADDR: 0 STACK: 10000 HEAP: 64
<Registers>
x0: 0 x1: 0 x2: 10000 x3: 64 x4: 48 x5: 0 x6: 0 x7: 0
x8: 0 x9: 0 x10: 64 x11: 28 x12: 64 x13: 64 x14: 0 x15: 0
x16: 0 x17: 0 x18: 0 x19: 0 x20: 0 x21: 0 x22: 0 x23: 0
x24: 0 x25: 0 x26: 0 x27: 0 x28: 0 x29: 0 x30: 0 x31: 0
あとは、これらの方法を使いプログラムを実装するだけである。Rinacoreは複数のファイルに分かれており、その中で重要なのがプログラムをロードするloader.mlと命令のデコードと実行を行うexec.mlである。元々RINANAは余興も見据えてminrtでは使わない命令もいくつか仕込んでいたので、命令のタイプと数が多い。そこでかなりの分量になると見込まれるexec.mlの実装はコア係と分担して行なった。コア係はVivadoでプロジェクトをビルドするたびに20-30分の待ち時間が発生する。最終段階にもなると、何度も修正が入り何度もビルドをすることになるのだが、その度にコードを書いてくれたので、かなり作業は順調に進んだ。いつもありがとう。
結局、CPU実験の発表会の前日の夕方から着手し1日で実装を終えた。Rinacoreの構想自体は前々から持っていたが、発表日直前に予定が立て込んでいたのでこのようなスケジュールになってしまった。突貫工事とはいえ、「あとは実装するだけ」という状態で始めたので、動作は割と安定しており、メモリをあまり必要とせず命令長が小さいプログラムに対してはテストした範囲ではちゃんと動作した。例えば、フィボナッチ数列の計算や、サイズを制限したmandelbrotは問題なく動く。
残念ながら動かないプログラムももちろん存在する。例えば、メモリの問題でminrtは動かない。また、rinacore on rinacoreも、rinacoreが上位に対して提供できるメモリはrinacoreが使用するメモリよりも当然少ないのでうまく動作しない。前者に関しては潤沢なメモリさえあれば動作すると踏んでいるが検証できていない。いずれにせよ、コアの上でfibやmandelbrotがrinacoreを介して動くのは見ていてかなり面白かった。
ちなみに、性能の低いFPGAボードに買い替えられて6以降、初めての余興だったらしい。7 実際、今のFPGAでは完動させるだけで一苦労で余興をする暇はないだろうし、早めに完動したとしても、そのような班は速度面での優勝が狙えるポテンシャルがあるので余興をするよりも高速化に専念するのが自然であろう。昔は早めに完動させてコアの上でLinuxを動かして遊ぶ人がいたと聞くので、そのような「余興を楽しめる」CPU実験が、FPGAの性能が落ちた今でも復活することを期待したい。
やってよかったこと 見出しへのリンク
1. アセンブラの更新の自動化 見出しへのリンク
コア係が作ったアセンブラr72bは、ISAの情報を外部のJSONファイルから取得するように実装されている。例えば、add命令は、
...
"add": {
"cor": {
"funct4": "0000",
"opcode": "000000"
},
"preset": "R-type"
},
...
というようなJSONによって定義され、これをr72bが読み込むことでaddが上手くアセンブルされる。こうすることで、ISAの変更があったときもソースコードを弄らなくてもJSONファイルを弄るだけで良いような実装になっている。
コア係による先を見据えたr72bの設計は非常に有り難かったが、人間とは怠惰なもので、ISAを変えるたびにJSONファイルを書き換えるのも億劫になってしまった。また、ISAの定義文書からJSONファイルへの移植の過程でopcodeを間違えてしまう人為的ミスが起こる可能性も否定できないという問題点も抱えていた。
そこで、ISAの定義文書からJSONファイルを自動生成するPythonスクリプトを作成した。これにより、ISAの変更があった時も、定義文書を書き換えるだけで勝手にr72bの更新が行われるので非常に快適性が増した。
2. minrtの実行結果をDiscord通知 見出しへのリンク
他の班の進捗発表で聞いた次の週に丸パクリする形で導入した。Makefileからdiscord通知を送るPythonスクリプトを叩くお手軽設計な割に、効果は絶大だった。副次的な効果として、コンパイラの現状の進捗をリアルタイムで班員に共有でき、今どれくらいの命令数でminrtが動くか、どの命令がネックとなり得るか等の情報をいち早く周知することができた。
Discord通知の例
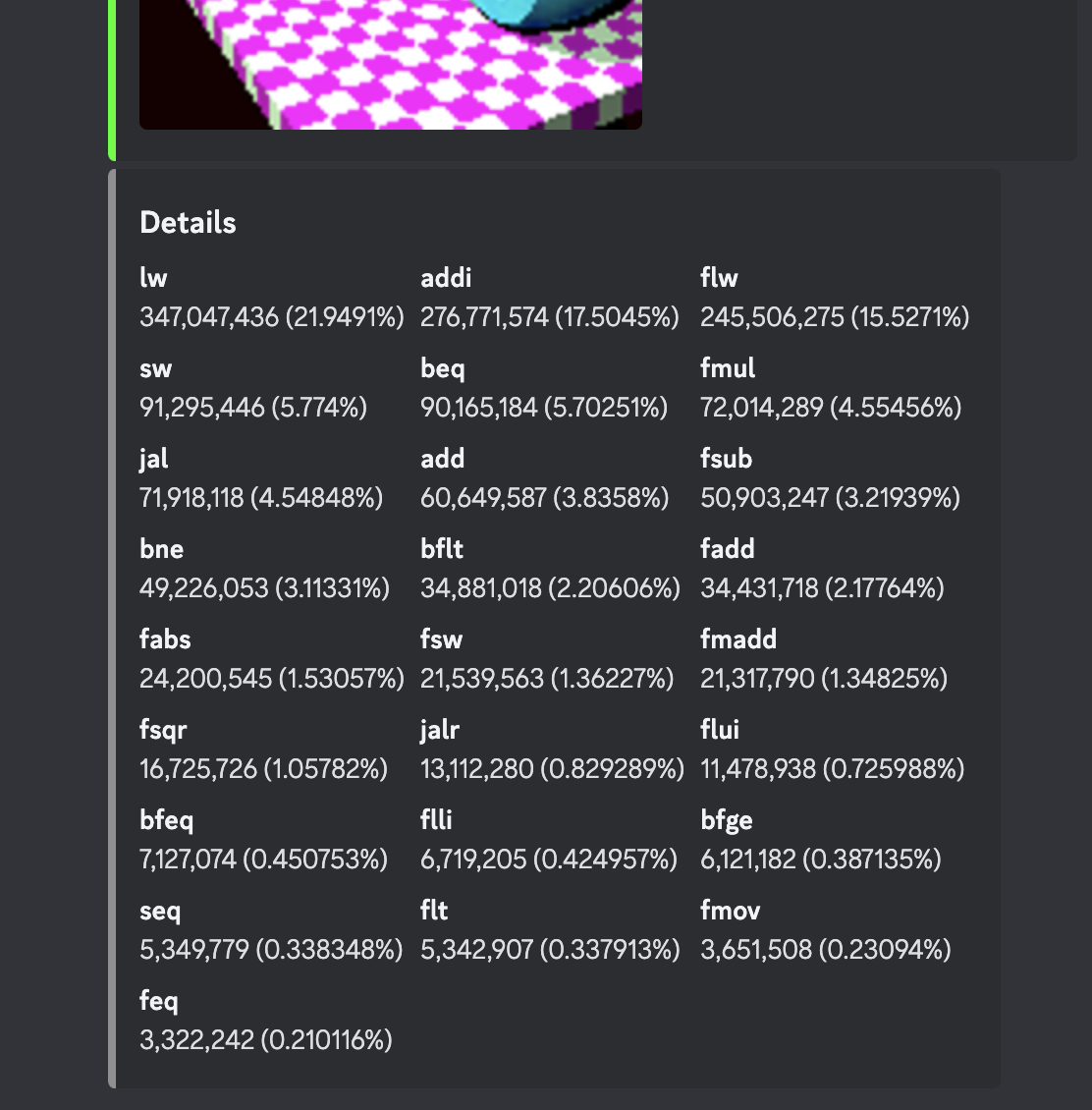
3. 気軽な「班内会議」 見出しへのリンク
「班内会議」というとかしこまった感じだが、ゲームをしながら、雑談を挟みつつ班の方向性や進捗共有、問題点について話した。あまり固くない場だったので気軽に開催・参加することができた。コア係はコアの仕様を話しながらvaloでヘッドショットを連発していた。恐ろしいマルチタスク能力。
全体としての感想 見出しへのリンク
ということで数ヶ月にも及ぶCPU実験がついに終わってしまった。率直な感想としては、「楽しかったが悔しい」。
このCPU実験では自分の「良いところ」「悪いところ」が本当によく見えたと思う。「良いところ」は誰も聞きたくないであろうから割愛するが、「悪いところ」として、リファクタリングを延々としてしまう癖と、自我を通すために過去の資料に当たるのを嫌ったことが挙げられるだろう。
まず、リファクタリングについて。CPU実験を通してかなり長い時間コンパイラのソースコードと向き合っていた自負があるが、そのほとんど(体感7割くらい)はリファクタリングに費やしていた。リファクタリングをし終わる頃には、さらにコンパイラの構造やHaskellに詳しくなるので、リファクタリングし終わった直後のコードさえも実態以上に冗長なものに思えて再度リファクタリングを行なってしまう。このループにCPU実験期間中に何度もはまっていた。過去にC++で自作言語のコンパイラを趣味で作っていたことがあるのだが、その時も「なんか違う」という理由だけですべてRustで書き換えてしまったことがある。8CPU実験においてもこの「なんか違う」は大量発生しており、ことあるごとに前に書いたコードが目について大規模なリファクタリングを行なってしまっていた。特にシミュ完動のために突貫工事で作ったback-endは何度も総とっかえが発生した。大規模な改装も厭わないのは良い面でもあるかもしれないが、CPU実験の発表会という「締め切り」があって「速度」で評価される以上、自分が思う綺麗なコンパイラを書いて浸っている場合ではなかったのではないかと思う。
次に、過去の資料に当たるのを嫌ったことについて。これは決して面倒だから当たらない、ということではない。普段は人並みに過去の資料を当たろうとするのだが、せっかくのCPU実験なので、過去の資料に頼ることなく自分自身で試行錯誤してコンパイラを作りたいという思いからあえてこの行動をとった。結果として「型を修めてからの型破りで、型を修めなければただの型無し」であるということを痛感した。試行錯誤する過程を知りたいのであれば、むしろ過去の資料をあたってCPU実験の「フロンティア」に辿り着いた上で思う存分自分自身の思うコンパイラを書けばよかったと思う。
「後悔先に立たず」なのでこの場で何を喚いても何も変わらないが、この記事をもし読んだ後輩がいるのならば、この2つには気をつけてほしい。いくらコードを書いても、ただただ周りからコンパイラの性能面で取り残される羽目になる。9楽しくはあるけどね。
最後に、班員の皆さん、そして色々面白い話をしてくれたコンパイラ係の皆さん、ありがとうございました。おかげでCPU実験を存分に楽しめました。
RINANAはRinana Is Not A Neat Assembly languageの頭文字をとって命名。決して理7をもじったわけではない。 ↩︎
minccはMincc Is Not a Complex Compilerの頭文字をとって命名。決してMINCaml Compilerの略ではない。 ↩︎
つまり、私と同じような人が来年以降いた場合、その人はこのブログを読まないはずだ。 ↩︎
IS24erのDiscord serverのemojiにもなっている。 ↩︎
もちろんstate monadでも良いが、構文的な問題でスッキリ書けないし、協力をしてもらったコア係にmonadの扱い方を理解してもらうのも酷なので、こちらの方針を取った。 ↩︎
数年前から、班に1台から全員に1台になる代わりに以前より安くスペックの低いFPGAになったらしい。 ↩︎
教授やTAからそう聞いたが、もしかしたら発表していないだけで余興を用意していた班が過去にあったかもしれない。少なくともIS24erでは我々の班だけだった。 ↩︎
周りに「なんで変えたか」と聞かれた時は、「C++だとメモリの管理が面倒でー」とか適当なことを言っていたが、実際はこの程度の感情で動いていた。 ↩︎
過去の資料に当たらない人は、そもそもこの資料に当たらないので、この忠告はかなり無駄ではある。 ↩︎