SECCON CTF 13の国内決勝にTSGのrev枠として参加し、3位を取ることができた。自分が張り付いていたAllegroの順位は8位だったので心境は複雑だが、ともあれwriteupを書きたいと思う。
King of the Hill: Allegro 見出しへのリンク
人生初のKing of the Hillとなった。 x86_64のバイナリが与えられ、そのバイナリの出力を変えずにいかに高速化できるかを競う問題であった。実質的にrevパートと最適化を行うパートに二分されていた。
より詳細なルールとしては、1ラウンド2-3時間で各ラウンドの最初にx86_64のバイナリが配布された。プレイヤーはそれを高速化したものを提出すると、5分おきに、そのプログラムが十分高速でかつテストを通る場合、その速度に応じた点が加算されていくというものであった。これが6ラウンド、つまり会場が空いている間ずっとあったので、Allegroを取り組むプレイヤーはこの問題に張り付いておかないといけなかった。
Round1: “普通"のx86_64のプログラム 見出しへのリンク
Ghidraでデコンパイルすると以下のようなCのコードが得られた。
long f(long param_1)
{
long lVar1;
long lVar2;
long lVar3;
if (param_1 == 0) {
param_1 = 1;
}
else if (param_1 == 1) {
param_1 = 1;
}
else if (param_1 == 2) {
param_1 = 1;
}
else {
lVar1 = f(param_1 + -3);
lVar2 = f(param_1 + -2);
lVar3 = f(param_1 + -1);
param_1 = param_1 + ((lVar1 + lVar2) - lVar3);
}
return param_1;
}
undefined8 main(void)
{
undefined8 uVar1;
long in_FS_OFFSET;
ulong local_18;
long local_10;
local_10 = *(long *)(in_FS_OFFSET + 0x28);
__isoc99_scanf(&DAT_00102004,&local_18);
if (3 < local_18) {
sleep(5);
}
uVar1 = f(local_18);
printf("%llu\n",uVar1);
if (local_10 != *(long *)(in_FS_OFFSET + 0x28)) {
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
return 0;
}
不要なsleep(5)を除去しつつ、fの再帰をループにして-O3オプションをつけてコンパイルして提出した。
#include <stdio.h>
int main(void) {
unsigned long long num;
scanf("%lld", &num);
if (num <= 2) {
puts("1");
return 0;
}
long long f0 = 1, f1 = 1, f2 = 1, fn = 0;
for (long i = 3; i <= num; i++) {
fn = i + ((f0 + f1) - f2);
f0 = f1;
f1 = f2;
f2 = fn;
}
printf("%llu\n", fn);
return 0;
}
結果は以下の通り。
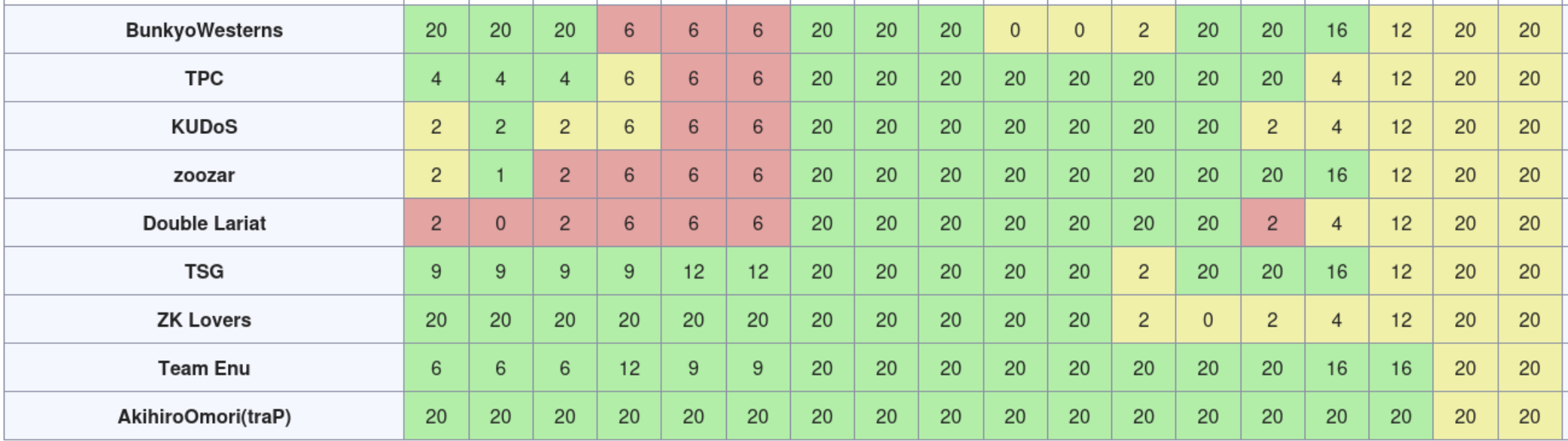
Round2: 難読化されたx86_64のプログラム 見出しへのリンク
Ghidraでサッとデコンパイルしても何しているかわからないプログラムが出てきた。stringsを使うと
UPX 4.24 Copyright (C) 1996-2024 the UPX Team. All Rights Reserved
と出てきたのでupx -dも試したが、流石に対策されているようでうまくいかなかった。改造したupxを使っているのだろう。
入力42を与えてstraceすると
...
read(0, "4", 1) = 1
clock_nanosleep(CLOCK_REALTIME, 0, {tv_sec=0, tv_nsec=1000000}, NULL) = 0
read(0, "2", 1) = 1
clock_nanosleep(CLOCK_REALTIME, 0, {tv_sec=0, tv_nsec=1000000}, NULL) = 0
read(0, "\n", 1) = 1
clock_nanosleep(CLOCK_REALTIME, 0, {tv_sec=0, tv_nsec=1000000}, NULL) = 0
read(0, "", 1) = 0
fstat(1, {st_mode=S_IFREG|0664, st_size=4563, ...}) = 0
write(1, "63b58bab\n", 963b58bab
) = 9
exit_group(0) = ?
+++ exited with 0 +++
という出力が得られた。1文字ずつreadして何かの操作を行なっているようなので、readにbreakpointsを設定してgdbデバッグを敢行し、以下のプログラムと同等であることを掴んだ。
x = input().encode()
res = 0xffffffff
for i in range(len(x)):
res ^= x[i]
for i in range(8):
res = (res >> 1) ^ (((0xffffffff + 1) - (res & 1)) & 0x82f63b78)
print(hex(0xffffffff & ~res))
これをCに書き直して提出したが時すでに遅し。しかもCへの移植をどこかミスしてしまったようである。
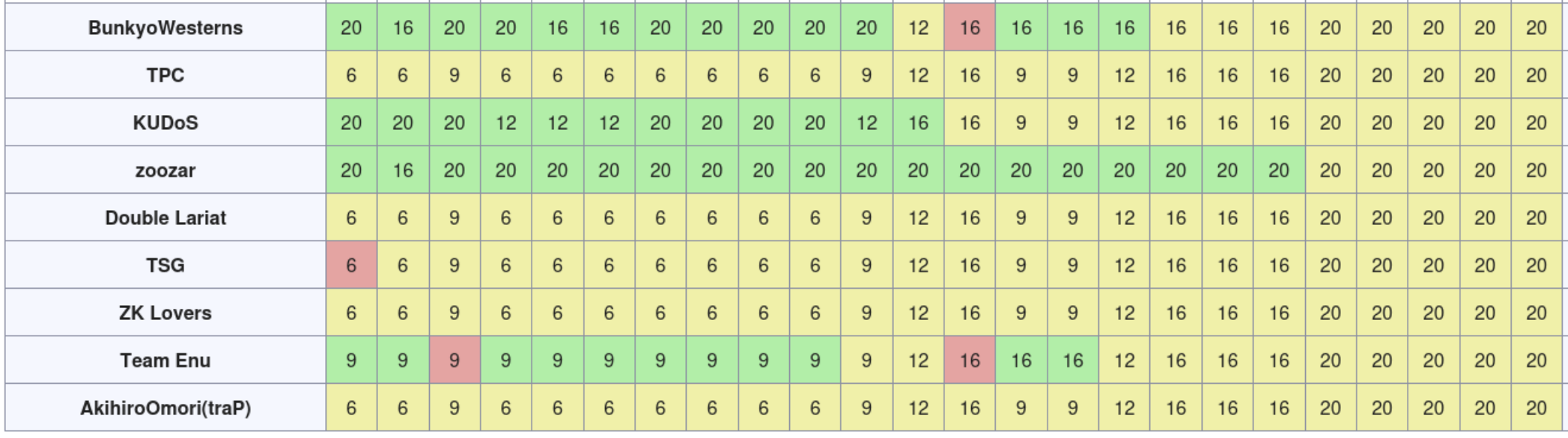
Round3: 独自VM風の何か 見出しへのリンク
Ghidraでデコンパイルすると以下のような見た目になる。OP1からOP9までの命令とレジスタR0からR9をもつVMで、最終的に結果としてレジスタの情報を出力することがわかる。関数のprefixからpythonで書かれていそうだが、問題にPythonの仕様絡みの話が関わってくることはなかった。
...
do {
if ((ulong)(long)iVar3 <= (ulong)local_48) {
for (local_78 = 0; local_78 < 10; local_78 = local_78 + 1) {
printf("R%ld: 0x%08x\n", local_78, (ulong) * (uint *)(local_38 + local_78 * 4 + -8));
}
uVar5 = 0;
return uVar5;
}
uVar6 = py_list_getitem(uVar5, (ulong)local_48 & 0xffffffff);
uVar7 = py_tuple_getitem(uVar6, 0);
uVar6 = py_tuple_getitem(uVar6, 1);
__s1 = (char *)py_tostr(uVar7);
iVar4 = strcmp(__s1, "OP1");
if (iVar4 == 0) {
vm_insn_op1(local_48, uVar6);
} else {
iVar4 = strcmp(__s1, "OP2");
if (iVar4 == 0) {
vm_insn_op2(local_48, uVar6);
} else {
iVar4 = strcmp(__s1, "OP3");
if (iVar4 == 0) {
vm_insn_op3(local_48, uVar6);
} else {
iVar4 = strcmp(__s1, "OP4");
if (iVar4 == 0) {
vm_insn_op4(local_48, uVar6);
} else {
iVar4 = strcmp(__s1, "OP5");
if (iVar4 == 0) {
vm_insn_op5(local_48, uVar6);
} else {
iVar4 = strcmp(__s1, "OP6");
if (iVar4 == 0) {
vm_insn_op6(local_48, uVar6);
} else {
iVar4 = strcmp(__s1, "OP7");
if (iVar4 == 0) {
vm_insn_op7(local_48, uVar6);
} else {
iVar4 = strcmp(__s1, "OP8");
if (iVar4 == 0) {
vm_insn_op8(local_48, uVar6);
} else {
iVar4 = strcmp(__s1, "OP9");
if (iVar4 != 0) {
fwrite("Invalid opcode\n", 1, 0xf, stderr);
uVar5 = 1;
goto LAB_00105511;
}
vm_insn_op9(local_48, uVar6);
}
}
}
}
}
}
}
}
local_48 = (undefined[8])((long)local_48 + 1);
} while (true);
...
ちなみにOP1は即値代入、OP2はmov、OP3-6は四則演算で、OP7はRISC-Vでいうところのbeq、OP8はbne、OP9はjmpであった。
仕様はわかったのであとはこれを実装すればいい。しかし、愚直な実装をすると、他チームより遅い結果になったり、最後の方に待っている厳しいテストケースを制限時間内に通過しなくなったりすることが想定されるので、JITするプログラムを実装することにした。方針としてはmprotectで適当に実行可能領域を確保してpwntoolsであらかじめ生成しておいたコード片から対応する命令を書き込んでいくことにした。ジャンプ命令が絡むものは仕方がないのでその場でディスアセンブルすることにした。
ただ、KoHの性質上、JITを実装している間も他チームに点が入り続けてしまうので、仮としてジャンプ命令をnopとしてみる嘘解法を提出した。通った場合は他のどのチームより高い点がもらえ、通らなかったとしても多くのチームがTLEしている関係上そこまで痛手にならない。結果的にこの作戦によりかなりの点を取ることに成功した。
結局、JITするプログラムはバグらせてしまったので、ただ嘘解法を提出しただけになってしまった。
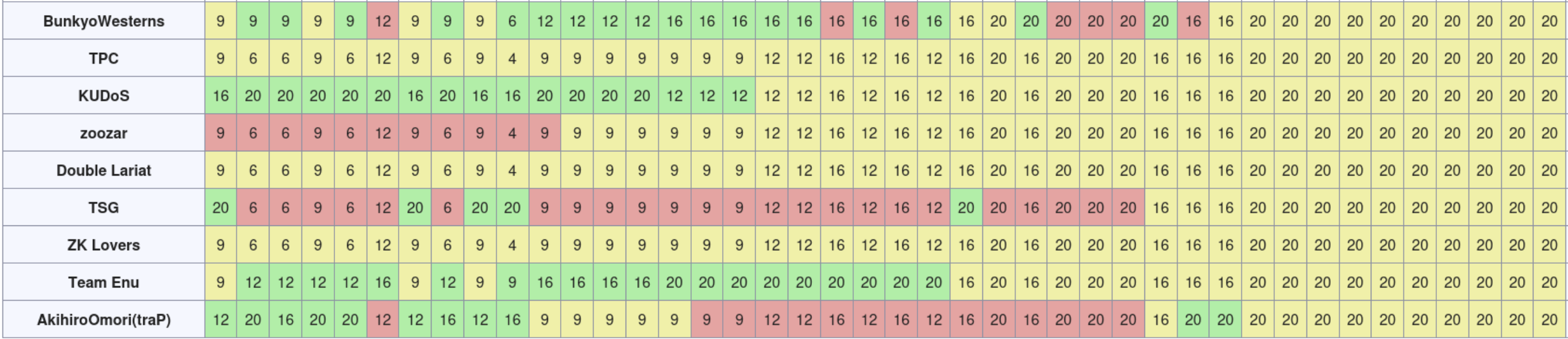
余談ではあるが、このバイナリはレジスタ番号が0-9の範囲内かどうかを判定していない。ゆえ、OP2を使ってレジスタRnの値をR0などのレジスタに読み出すことで範囲外参照をすることができ、本来読めないメモリ上の値を読み出すことができる。“真に"挙動を再現するべきであるならば、この脆弱性も再現する必要があったのだろう。
Round4: Python 見出しへのリンク
straceをすると、
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7f767f42f350) = 96023
と言う部分があり、cloneを使って新しいプロセスを作っていることがわかる。cloneされた後の処理を追うためにgdbでデバッグしていると大量のPyEval_EvalCodeに遭遇した。どうやらcpythonを呼んでPythonのバイトコードを実行しているプログラムのようである。
あとはPythonのバイトコードを抽出したい。cpythonのソースコードを読んだりネット検索を行ったりした結果、PyEval_EvalCodeが内部で呼んでいる_PyEval_EvalFrameDefaultの引数がどうやらPythonのバイトコードを保持しているようだということがわかった。しかし、最後までどのような形式で格納されているのか掴めずに時間を浪費し、結局何も提出できずに終わってしまった。
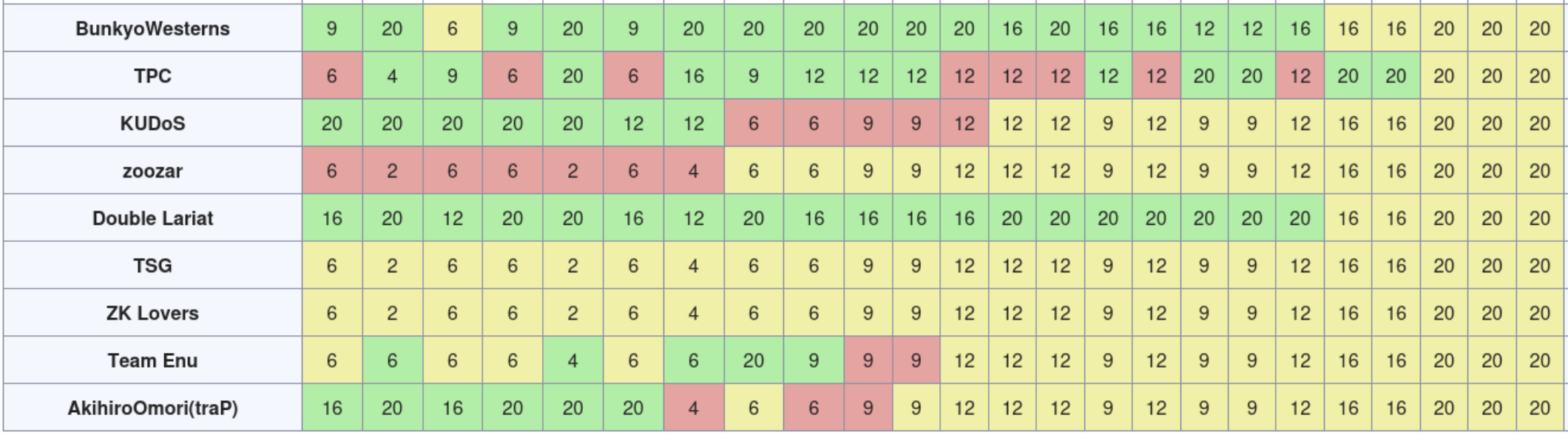
余談ではあるが、この問題が出て割とすぐに会場中から「Pythonかぁ〜」という落胆のような声がいくつか聞こえた。“素直な"x86_64のバイナリはもうお目にかかれないのだろうな、と皆思ったのかもしれない。
Round5: Lua 見出しへのリンク
Ghidraでデコンパイルすると以下の通り。Luaのバイトコードを実行していることがわかる。
undefined8 main(void)
{
int iVar1;
undefined8 uVar2;
long in_FS_OFFSET;
ulong local_58;
undefined8 local_50;
ulong local_48;
ulong local_40;
ulong local_38;
ulong local_30;
ulong local_28;
ulong local_20;
long local_18;
long local_10;
local_10 = *(long *)(in_FS_OFFSET + 0x28);
local_18 = luaL_newstate();
if (local_18 == 0) {
uVar2 = 1;
}
else {
iVar1 = luaL_loadbufferx(local_18,&bytecode,0xfffffffff2e80000,"embedded",0);
if ((iVar1 == 0) && (iVar1 = lua_pcallk(local_18,0,0xffffffff,0,0,0), iVar1 == 0)) {
__isoc99_scanf(&DAT_004c13c1,&local_58);
lua_getglobal(local_18,&DAT_004c13c5);
lua_getglobal(local_18,&DAT_004c13c7);
lua_getglobal(local_18,&DAT_004c13c7);
lua_createtable(local_18,local_58 & 0xffffffff,0);
for (local_48 = 0; local_48 < local_58; local_48 = local_48 + 1) {
lua_createtable(local_18,local_58 & 0xffffffff,0);
for (local_40 = 0; local_40 < local_58; local_40 = local_40 + 1) {
__isoc99_scanf(&DAT_004c13c9,&local_50);
lua_pushinteger(local_18,local_50);
lua_rawseti(local_18,0xfffffffe,local_40 + 1);
}
lua_rawseti(local_18,0xfffffffe,local_48 + 1);
}
lua_createtable(local_18,local_58 & 0xffffffff,0);
for (local_38 = 0; local_38 < local_58; local_38 = local_38 + 1) {
lua_createtable(local_18,local_58 & 0xffffffff,0);
for (local_30 = 0; local_30 < local_58; local_30 = local_30 + 1) {
__isoc99_scanf(&DAT_004c13c9,&local_50);
lua_pushinteger(local_18,local_50);
lua_rawseti(local_18,0xfffffffe,local_30 + 1);
}
lua_rawseti(local_18,0xfffffffe,local_38 + 1);
}
iVar1 = lua_pcallk(local_18,2,1,0,0,0);
if (iVar1 == 0) {
lua_pushvalue(local_18,0xffffffff);
iVar1 = lua_pcallk(local_18,2,1,0,0,0);
if ((iVar1 == 0) && (iVar1 = lua_pcallk(local_18,1,1,0,0,0), iVar1 == 0)) {
for (local_28 = 0; local_28 < local_58; local_28 = local_28 + 1) {
lua_rawgeti(local_18,0xffffffff,local_28 + 1);
putchar(0x5b);
for (local_20 = 0; local_20 < local_58; local_20 = local_20 + 1) {
lua_rawgeti(local_18,0xffffffff,local_20 + 1);
if (local_20 == local_58 - 1) {
uVar2 = lua_tointegerx(local_18,0xffffffff,0);
printf("%lld",uVar2);
}
else {
uVar2 = lua_tointegerx(local_18,0xffffffff,0);
printf("%lld, ",uVar2);
}
lua_settop(local_18,0xfffffffe);
}
puts("]");
lua_settop(local_18,0xfffffffe);
}
}
}
}
lua_close(local_18);
uVar2 = 0;
}
if (local_10 == *(long *)(in_FS_OFFSET + 0x28)) {
return uVar2;
}
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
幸いなことに、Pythonの時と異なり、bytecodeという名前のsymbolが残っているので簡単にluaのバイトコードを取り出すことができた。問題はluaのバージョンであるが、stringsすると、
$LuaVersion: Lua 5.4.6 Copyright (C) 1994-2023 Lua.org, PUC-Rio $$LuaAuthors: R. Ierusalimschy, L. H. de Figueiredo, W. Celes $
という文字列が見つかったので、Lua 5.4.6とみて良いだろう。すぐにlua 5.4.6をダウンロードしてきてluacを使ってバイトコードを復号し以下のようなもの(一部割愛)を得た。
main <main.lua:0,0> (8 instructions at 0x55ad1e4a0c80)
0+ params, 2 slots, 1 upvalue, 0 locals, 3 constants, 3 functions
1 [1] VARARGPREP 0
2 [12] CLOSURE 0 0 ; 0x55ad1e4a0e80
3 [1] SETTABUP 0 0 0 ; _ENV "H"
4 [23] CLOSURE 0 1 ; 0x55ad1e4a1140
5 [14] SETTABUP 0 1 0 ; _ENV "G"
6 [37] CLOSURE 0 2 ; 0x55ad1e4a1390
7 [25] SETTABUP 0 2 0 ; _ENV "F"
8 [37] RETURN 0 1 1 ; 0 out
constants (3) for 0x55ad1e4a0c80:
0 S "H"
1 S "G"
2 S "F"
locals (0) for 0x55ad1e4a0c80:
upvalues (1) for 0x55ad1e4a0c80:
0 _ENV 1 0
function <main.lua:1,12> (19 instructions at 0x55ad1e4a0e80)
3 params, 7 slots, 0 upvalues, 11 locals, 0 constants, 0 functions
1 [2] LTI 2 0 0
2 [2] JMP 8 ; to 11
3 [3] LOADI 3 1
4 [3] UNM 4 2
5 [3] LOADI 5 1
6 [3] FORPREP 3 2 ; exit to 10
7 [4] SUB 0 0 1
8 [4] MMBIN 0 1 7 ; __sub
9 [3] FORLOOP 3 3 ; to 7
10 [5] JMP 7 ; to 18
11 [7] LOADI 3 1
12 [7] MOVE 4 2
13 [7] LOADI 5 1
14 [7] FORPREP 3 2 ; exit to 18
15 [8] ADD 0 0 1
16 [8] MMBIN 0 1 6 ; __add
17 [7] FORLOOP 3 3 ; to 15
18 [11] RETURN1 0
19 [12] RETURN0
constants (0) for 0x55ad1e4a0e80:
locals (11) for 0x55ad1e4a0e80:
0 a 1 20
1 b 1 20
2 c 1 20
3 (for state) 6 10
4 (for state) 6 10
5 (for state) 6 10
6 i 7 9
7 (for state) 14 18
8 (for state) 14 18
9 (for state) 14 18
10 i 15 17
...
どうやら3重ループを回しているようである。最初はこれを真面目に解析しようと試みて、かなりの時間を溶かした。
途中で、入力形式が数字\(n\)とそれに続いて\(2n^2\)個の数字が与えられるものであることと、3重ループという計算量から何かしらの行列計算であると踏んで処理内容をエスパーする方向に転換した。行列の対角成分の1つを\(m\)倍にすると結果の値が\(m^2\)倍で反応することや、単位行列を与えるともう片方の行列の2次式が帰ってくることなどから推察して、最終的に\((B^\top A^\top)(B^\top A^\top)\)であるという結論に達した。
あとはこれを計算するCのコードを書いて提出した。
#include <stdio.h>
#include <stdlib.h>
void matmul(long long n, long long **a, long long **b, long long **result) {
for (long long i = 0; i < n; i++) {
for (long long j = 0; j < n; j++) {
result[i][j] = 0;
for (long long k = 0; k < n; k++) {
result[i][j] += a[i][k] * b[k][j];
}
}
}
}
int main() {
long long a;
scanf("%lld", &a);
long long **b = (long long **)malloc(a * sizeof(long long *));
long long **c = (long long **)malloc(a * sizeof(long long *));
long long **bc = (long long **)malloc(a * sizeof(long long *));
long long **bc_bc = (long long **)malloc(a * sizeof(long long *));
for (long long i = 0; i < a; i++) {
b[i] = (long long *)malloc(a * sizeof(long long));
c[i] = (long long *)malloc(a * sizeof(long long));
bc[i] = (long long *)malloc(a * sizeof(long long));
bc_bc[i] = (long long *)malloc(a * sizeof(long long));
}
long long prev = 0;
for (long long i = 0; i < a; i++) {
for (long long j = 0; j < a; j++) {
if(scanf("%lld", &b[j][i]) < 0) {
b[j][i] = prev;
}
prev = b[j][i];
}
}
for (long long i = 0; i < a; i++) {
for (long long j = 0; j < a; j++) {
if(scanf("%lld", &c[j][i]) < 0) {
c[j][i] = prev;
}
prev = c[j][i];
}
}
matmul(a, c, b, bc);
matmul(a, bc, bc, bc_bc);
for (long long i = 0; i < a; i++) {
putchar('[');
for (long long j = 0; j < a - 1; j++) {
printf("%lld, ", bc_bc[i][j]);
}
printf("%lld", bc_bc[i][a - 1]);
puts("]");
}
return 0;
}
最初のバージョンでは誤って行列をローカル変数として定義してしまったがために、大きい入力が来るとスタック領域を食い潰してエラー落ちするという初歩的なミスを犯してしまった。エスパーして解答を得ていたので、「もしかしたら"本当の式"はこれではないのかもしれない」と疑ってプログラムの誤りを疑わなかったので、結構なラウンドをドブに捨ててしまった。
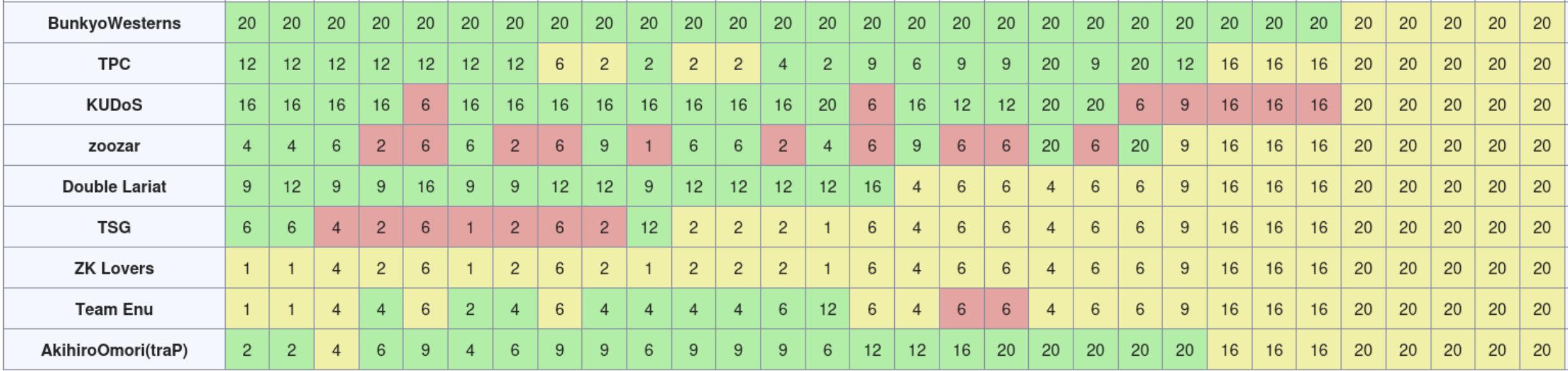
余談ではあるが、この問題が出て割とすぐに会場中から「Luaかぁ〜」という落胆のような声がいくつか聞こえた。
Round6: 無意味な演算を大量に含んだbit演算 見出しへのリンク
とりあえずGhidraにかけると、以下のようなCPUの情報をとってくる無意味なコードが大量に混じっていることがわかった。
...
if (iVar5 == 0) {
cpuid_basic_info(0);
}
else if (iVar5 == 1) {
cpuid_Version_info(1);
}
else if (iVar5 == 2) {
cpuid_cache_tlb_info(2);
}
else if (iVar5 == 3) {
cpuid_serial_info(3);
}
else if (iVar5 == 4) {
cpuid_Deterministic_Cache_Parameters_info(4);
}
else if (iVar5 == 5) {
cpuid_MONITOR_MWAIT_Features_info(5);
}
else if (iVar5 == 6) {
cpuid_Thermal_Power_Management_info(6);
}
else if (iVar5 == 7) {
cpuid_Extended_Feature_Enumeration_info(7);
}
...
とりあえずこれらを一括置換で消してしまっても良いか、と思ったが、
n = cpu_id(0);
...
m = cpu_id(0);
...
ans += n / m;
のように環境に依存しない定数を作り出して計算結果に混ぜている可能性が否定できなかったので、手動で除去をした。結果的には杞憂であったので数分無駄にしてしまったが依存している場合に沼にハマっていたと思うのでやって良かったと思う。
そうすると以下のようなコード(一部割愛)を得る。
int main(void)
{
// ...
for (local_48 = 0; local_48 < local_58; local_48 = local_48 + 1) {
iVar4 = (int)local_58;
iVar4 = *piVar1;
local_50 = 0;
uVar12 = (unsigned long)*puVar2;
for (local_40 = 0; iVar4 = (int)uVar12, local_40 < 0x20; local_40 = local_40 + 1) {
uVar12 = (unsigned long)((unsigned int)(local_68 >> ((unsigned char)local_40 * '\x02' & 0x3f)) & 1) <<
((unsigned char)local_40 & 0x3f);
local_50 = local_50 + uVar12;
}
uVar12 = (unsigned long)*puVar2;
for (local_38 = 0; iVar4 = (int)uVar12, local_38 < 0x20; local_38 = local_38 + 1) {
uVar12 = (unsigned long)((unsigned int)(local_68 >> ((char)local_38 * '\x02' + 1U & 0x3f)) & 1) <<
((char)local_38 + 0x20U & 0x3f);
local_50 = local_50 + uVar12;
}
bVar3 = 0;
uVar12 = local_50;
for (local_28 = 0; local_28 < 0x40; local_28 = local_28 + 1) {
iVar4 = (int)uVar12;
uVar13 = local_60 >> ((unsigned char)local_28 & 0x3f);
uVar5 = (unsigned int)uVar13 & 1;
uVar12 = (unsigned long)uVar5;
if (uVar12 != 0) {
uVar12 = (unsigned long)*puVar2;
bVar3 = bVar3 + 1;
}
}
local_60 = local_60 ^ local_50 << (bVar3 & 0x3f);
iVar4 = (int)local_60;
uVar5 = (unsigned int)(local_60 >> 7) & 1;
uVar6 = (int)(local_60 >> 0xf) * 2 & 2;
uVar12 = (local_60 >> 0x17) << 2;
uVar7 = (unsigned int)uVar12 & 4;
uVar12 = (local_60 >> 0x1f) << 3;
uVar8 = (unsigned int)uVar12 & 8;
uVar12 = (local_60 >> 0x27) << 4;
uVar9 = (unsigned int)uVar12 & 0x10;
uVar12 = (local_60 >> 0x2f) << 5;
uVar10 = (unsigned int)uVar12 & 0x20;
uVar12 = (local_60 >> 0x37) << 6;
uVar11 = (unsigned int)uVar12 & 0x40;
lVar14 = ((long)local_60 >> 0x3f) * -0x80;
local_30 = (unsigned long)uVar5 + (unsigned long)uVar6 + (unsigned long)uVar7 + (unsigned long)uVar8 + (unsigned long)uVar9 +
(unsigned long)uVar10 + (unsigned long)uVar11 + lVar14;
iVar4 = (int)lVar14;
local_50 = local_50 ^ local_60 << ((unsigned char)local_30 & 0x3f);
iVar4 = (int)local_50;
local_60 = local_50 ^ local_60;
iVar4 = (int)local_60;
iVar4 = (int)(local_50 << 0x18);
lVar14 = (local_50 >> 0x18 & 0xff) * 0x100;
iVar4 = (int)lVar14;
uVar12 = (local_50 >> 0x28) << 0x10;
uVar5 = (unsigned int)uVar12 & 0xff0000;
uVar12 = local_50 >> 0x30 & 0xff;
iVar4 = (int)uVar12;
local_68 = (local_50 << 0x18 & 0xffffffff) + ((local_50 >> 8) << 0x38) +
((local_50 >> 0x10 & 0xff) << 0x30) + lVar14 + (local_50 & 0xff00000000) +
(unsigned long)uVar5 + uVar12 + ((local_50 >> 0x38) << 0x28);
uVar12 = (unsigned long)*(unsigned int *)(lVar14 + 8);
local_50 = local_68;
}
printf("%lu\n",local_68);
return 0;
}
これを整理すると、
#include <stdio.h>
int main(void) {
// ...
scanf("%lu", &loop_counter);
scanf("%lu", &ans);
scanf("%lu", &local_60);
for (unsigned long i = 0; i < loop_counter; i++) {
local_50 = 0;
for (local_40 = 0; local_40 < 0x20; local_40++) {
local_50 += (unsigned long)((unsigned int)(ans >> ((unsigned char)local_40 * 2)) & 1) << ((unsigned char)local_40);
local_50 += (unsigned long)((unsigned int)(ans >> ((char)local_40 * 2 + 1U)) & 1) << ((char)local_40 + 0x20U);
}
bVar3 = 0;
for (j = 0; j < 0x40; j++) {
bVar3 += (local_60 >> j) & 1;
}
local_60 ^= local_50 << bVar3;
uVar5 = local_60 >> 7 & 1;
uVar6 = ((local_60 >> 0xf & 1) << 1);
uVar7 = ((local_60 >> 0x17 & 1) << 2);
uVar8 = ((local_60 >> 0x1f & 1) << 3);
uVar9 = ((local_60 >> 0x27 & 1) << 4);
local_30 = uVar5 + uVar6 +
uVar7 + uVar8 +
uVar9;
local_50 ^= local_60 << (local_30 & 0x3f);
local_60 ^= local_50;
ans = (local_50 << 0x18 & 0xffffffff)
+ ((local_50 >> 8) << 0x38)
+ ((local_50 >> 0x10 & 0xff) << 0x30)
+ ((local_50 >> 0x18 & 0xff) << 0x8)
+ (local_50 & 0xff00000000)
+ (((local_50 >> 0x28 & 0xff) << 0x10))
+ (local_50 >> 0x30 & 0xff)
+ ((local_50 >> 0x38) << 0x28);
}
printf("%lu\n", ans);
return 0;
}
となる。また、
for (j = 0; j < 0x40; j++) {
bVar3 += (local_60 >> j) & 1;
}
はlocal60のbitの合計をとっているだけなのでpopcnt命令で計算することができる。ただ、これ以降の最適化を競技中には思いつくことができず、このまま提出したがこの段階ではテストケースの難易度が相当上がっていたようで時間制限に引っかかってしまった。しかも、最適化のためにコードをいじる時に誤って入力に%luではなく%ldを用いるよう書き換えてしまったようで、入力が大きい場合に正しく動作しないという致命的なバグを作ってしまった。Git等でバージョン管理した方が良かったかもしれない。
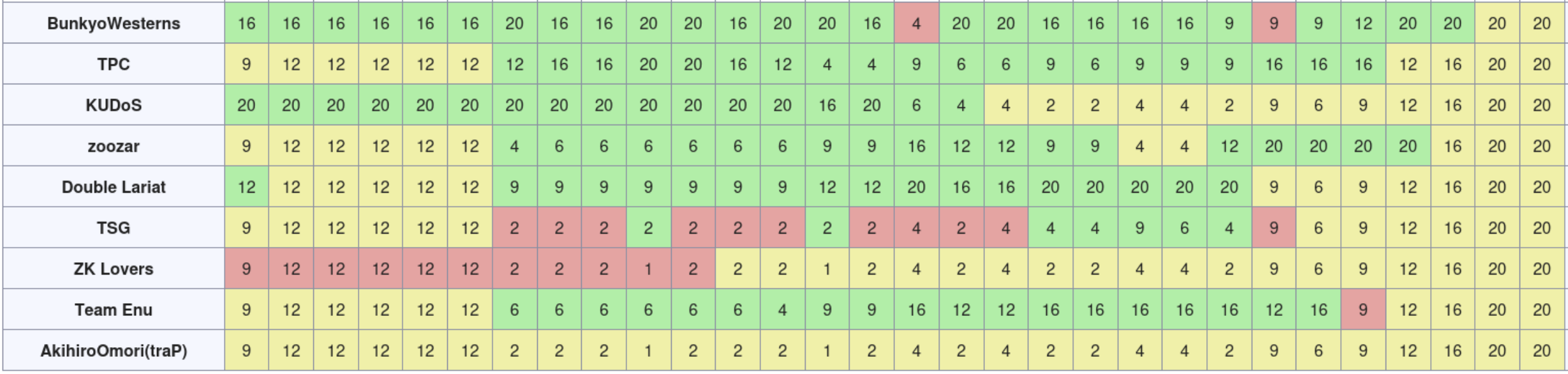
競技後に人から聞いた話ではpext命令等を用いると良いとのことだった。
最後に 見出しへのリンク
運営の皆さん2日間ありがとうございました。もっと知識と技術をつけて出直してきます。
(付録1) 時間の使い方 見出しへのリンク
会場にいる間はずっとAllegroにかかりっきりで、1日目と2日目の間はConnect_Sixに手をつけていた。石を積み上げてメモリ領域を破壊できる脆弱性とscoreが未初期化である脆弱性を見つけ、ガチャガチャやっても解けないまま2日目になっていた。
(付録2) 会場の様子 見出しへのリンク
会場は以下のような場所で各チームにテーブルが与えられている。2日目の競技開始前の様子だが、案外殺伐とした雰囲気ではなかった。

各チームのテーブルにはパネルとチーム名とアイコンが描かれた横断幕が設置されていた。

会場の隣にはAlpaca Hackのブースがあり、アルパカのぬいぐるみが置かれていた。かわいい。会場随一の癒し。